
There’s nothing more satisfying than winning a staff-room or pub argument about what works and what doesn’t by quoting effect sizes. There they are, in black and white: stats that show you are right. Homework is rubbish, class sizes don’t matter, feedback is king. However, my concern is that effect sizes in the hands of uninitiated are educational accidents waiting to happen. There are a few things to take into account before you swallow the evidence…
What are effect sizes and why are they useful?
Effect sizes are a way of showing the statistical significance of a data set. Put simply, they are useful because they show the difference in outcomes between a test group (which has been given a specific intervention) and a control group (which has had no change to their teaching). The reason they are useful is that they can show the size of the difference between two groups.
For example, imagine an experiment where two groups of 30 pupils had been taught using different strategies and showed a gap in test results of 10%. It seems logical to say that this intervention has been worthwhile. However, what if all 30 of the pupils who received the intervention scored above all the ones in the control group? This would make it even more significant, because it worked for everyone. On the contrary, if the 10% difference came from only 5 pupils who did incredibly well, but the other 25 were pretty much the same as the 30 in the control group, it wouldn’t seem so earth-shattering.
This is where effect sizes come in. If you want to get chapter and verse on how they’re calculated then read Rob Coe’s ‘It’s the Effect Size, Stupid!’ What the effect size does is takes into account the spread of results (the standard deviation). This means that you get a deeper understanding through the context of the results.
Unpacking effect sizes
However, there are a lot of teachers (and school leaders) who bang on about effect sizes as if they are the only thing that matters. According to John Hattie, anything with an effect size of 0.4 or above is meaningful, and above 0.6 has high impact. This has led to lots of stats being parroted in teacher discussions to show which strategies and interventions are the most effective and should therefore be followed without hesitation. Looking at lengthy tables like this would seem to spell out with great clarity what works and what doesn’t:
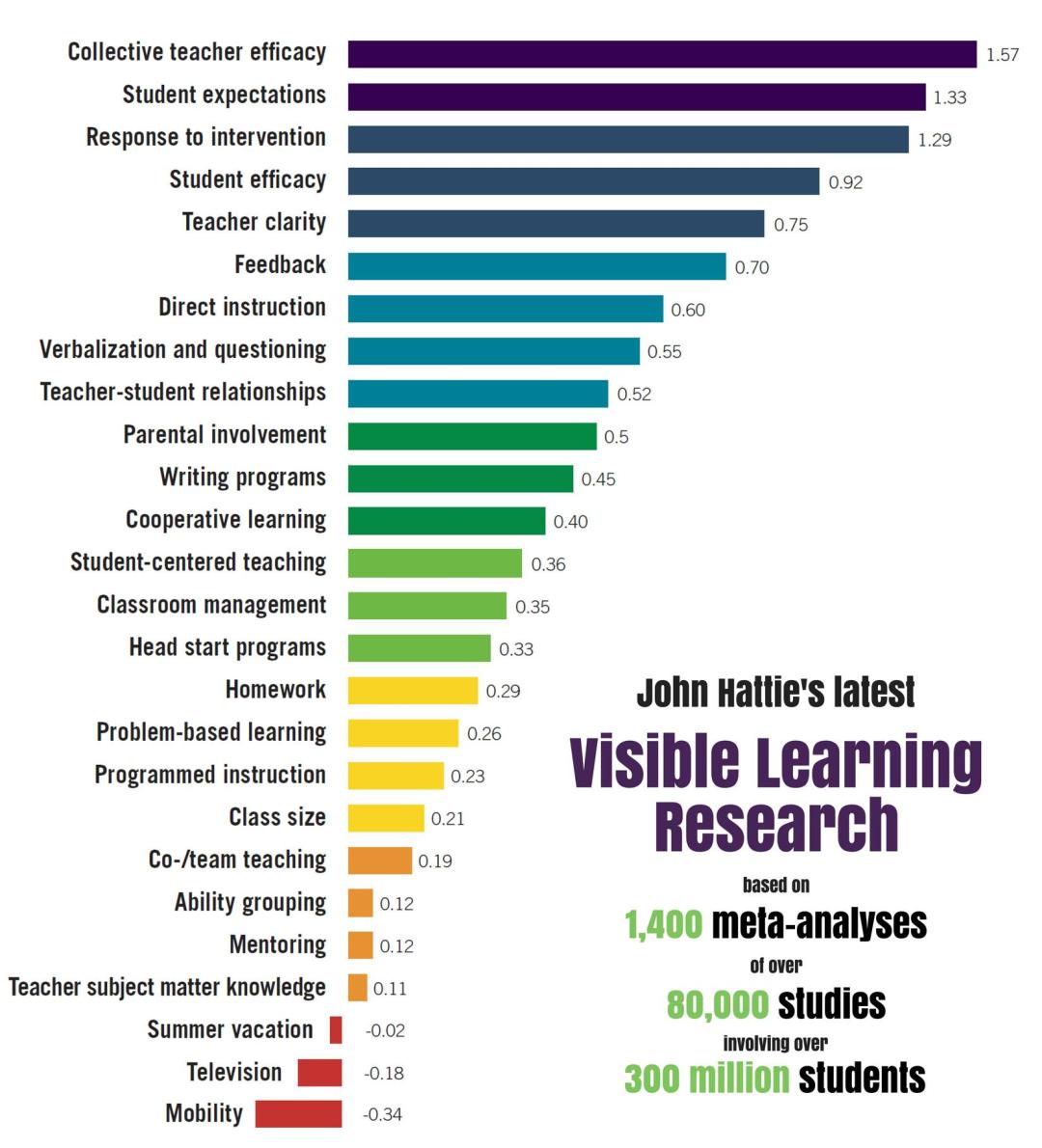
Sadly, it isn’t that simple. Within these stats lie substantial variation. The classic example is homework – quoted here at a modest 0.29. However as various blogs and authors have pointed out (most effectively Tom Sherrington in the Learning Rainforest), the picture changes when we look at primary homework (a paltry 0.15) and secondary (a game-changing 0.64). The older the pupil, the more valuable homework is. Hattie has also pointed out that research is based on what has been done up to now. It may be that primary homework can be set in the future which has greater efficacy, and could change the numbers up the way.
A shift in thinking
What interested me this week was listening to Ollie Lovell’s (@ollie_lovell) thoughts on Craig Barton’s podcast episode ‘A Slice of Advice’. He subsequently wrote this blog post in which he uses his interviews with Adrian Simpson and John Hattie to explain his thinking. What emerges is the problem that an effect size can vary depending on how the experiment is designed, rather than the impact of the intervention. Based on this, Ollie rejects the use of effect sizes and calls them a ‘category error’.
I’m intrigued by this and it represents a significant shift in thinking if we’re going to abandon effect sizes (and the ranking of them) as a meaningful way of evaluating strategies and interventions. I suspect this is a debate that is about to explode, and in all honesty I don’t yet know where I stand on it. I did think the most persuasive point Ollie makes is this:
“Has an effect size ever made me a better teacher? I honestly couldn’t think of an example that would enable me to answer ‘yes’ to this question.”
With that, I have to agree. I also give a lot of respect to Ollie for tackling this head on. He’s ventured into a field that few would have ever considered to question.
Baby and bathwater?
We all know that there are lies, damned lies and statistics. However, Hattie makes a good point: what else are we going to use? I’m not a researcher but a teacher (and not a Maths one at that too), so what I say next should be taken in that context. At present I kick against the trend of effect sizes being quoted haphazardly by teachers in debates as I usually find this reductive. However, until there is a better method of expressing the value of an intervention I think we need to train teachers to be able to reach the story behind the numbers (as Hattie says) or understand the mechanisms (as Simpson says). If the numbers are less reliable than we thought, imagine how much distortion in practice is caused by their blind application in classrooms. While the debate rages effect sizes will continue to be used, so let’s do so with more care than before. Remember, the effect size is the headline, not the article. You need to read on…

I think the move away from tallying positive and negative significant results and towards effect sizes is one of the most important developments in the behavioural sciences in the last half-century. Some kind of measure of the magnitude of effects is absolutely essential, and although we can argue about what are the best measures for doing this, Cohen’s standardized effect size is a reasonable starting point.
However, the effect size needs to be considered alongside three other factors. The first is the cost of the intervention. A tiny effect size, such as the one month’s extra learning produced by the READY4K! initiative, is educationally important, since it costs only around $10 per student. And class-size reduction, although it can improve student achievement substantially, particularly for younger and at-risk students, it is very expensive, and there are better things to do with the money.
The second is the quality of evidence. Where the evidence shows that the intervention has a dramatic positive effect in some cases, and a dramatic negative effect in others, even if the average effect is positive, we should be cautious about implementation. For example, from his meta-meta-analyses, Hattie concludes that the recipe for improving education is “dollops of feedback”, presumably because he finds that feedback has an effect size around 0.8. But Kluger and DeNisi in their careful review of feedback studies (Kluger & DeNisi, 1996), found that in 38% of cases, feedback actually lowered performance. Until we understand when feedback increases, and when it decreases, achievement, a bland prescription to give more feedback might actually make things worse. Teachers need to be critical consumers of research evidence.
The third is the need to ensure that the intervention solves a problem that one actually has. Many advocates of merit pay for teachers cite evidence from Kenya and India where teacher performance did improve achievement. However, this seems to have occurred largely through increasing teacher attendance, which is a real problem in those countries. If teacher attendance is good, incentives that increase teacher attendance are unlikely to help.
If we take these cautions into account, then effect sizes can help teachers decide where to invest their efforts. Effect sizes won’t magically improve teachers, but it will help them avoid wasting time on things that have little impact on student achievement.
LikeLiked by 1 person
Thanks Dylan. Some really important caveats here and I agree wholeheartedly that teachers need to be critical consumers – I think that’s where we’re falling down just now. More training should be geared towards that skillset. The third point about the intervention solving the problem identified is related because school leaders get this wrong too often. Avoiding time wasting should be at the forefront of strategic planning but often comes as an afterthought, or even worse, not at all.
LikeLike
Thanks Dylan for a dose of common sense. The rise of standardised assessment in Scottish education needs to be tempered by more thought about the educational purpose behind the assesment.
LikeLike
Reblogged this on The Echo Chamber.
LikeLiked by 1 person
A new paper just out by Simpson (https://goo.gl/Txnk23) shows that the interpretation of effect size as effectiveness doesn’t really work and explains in detail the category error phrase. He gives examples of where identical interventions have very different effect sizes depending on how the study is designed: “Understanding that effect size is a property of the whole study, not just the intervention, may help us avoid reifying concepts such as the ‘effectiveness of the intervention’, which may have little straightforward meaning.
For example, the meaning of ‘the effect of feedback’ is far from clear. ‘Evidence‐based education’ proponents often claim inspiration from pharmacology, yet we would dismiss arguments about ‘the effect of aspirin’ that drew on studies of aspirin against a placebo, aspirin against paracetamol, aspirin against an antacid and aspirin against warfarin on measures as diverse as blood pressure, wound healing, headache pain and heart attack survival. Yet we are asked to believe in an ‘effect for instructional technology’ based on comparing interactive tutorials to human tutoring, to reading text, to ‘traditional instruction’ and to not being taught the topic at all, on outcomes as diverse as understanding the central limit theorem, writing simple computer programs, completing spatial transformations and filling out account books.”
Unless a study had the same design as another we shouldn’t compare effect sizes to conclude about better interventions (even takking account of cost, quality of evidence and context as Dylan says). I’m with Ollie in saying that effect size as a way of deciding what to do (or not what to do) in the class is discredited.
LikeLike